Following up on my earlier submit about figuring out web sites that scrape content material and discovering out their IP and internet hosting supplier, this text covers stopping these web sites from scaping your content material.
As a reminder, the unfavorable impression of scrapers is up for debate. In principle, Google ought to ignore these, and for those who do a website search of a scraper (website:scraperdoman.com), you’ll sometimes see only a few pages listed.
Due to this fact, it could possibly be argued that spending hours each month or two filling DMCA requests is a waste of time.
On the flip aspect, some individuals have theorised that one of many points web sites have skilled with the Google Useful Content material Replace is expounded to poor backlinks profiles partly attributable to scrapers. However, in fact, the official phrase from Google has all the time been that these don’t matter, they only get ignored.
Submitting DMCA / Copyright Takedown Notices
In case you have efficiently recognized the internet hosting supplier of an internet site scraping your content material, then the perfect guess is to submit a DMCA request to their host.
Some hosts ignore them, however most don’t. From my expertise, many scrapers don’t reply to the DMCA request, and the web site will get taken down, which all the time offers me a little bit of satisfaction.
Many will take away your content material and cease scraping. Some will simply take away the content material you listed and proceed scraping.
To start with, seek for the internet hosting supplier + DMCA, and you’ll usually discover the official coverage on these requests. More often than not, you simply electronic mail [email protected].
You’ll then must get a listing of the posts which have been scraped and the corresponding authentic URLs. I sometimes solely get a number of URLs, simply sufficient to show they’re scraping.
You’ll then wish to place all of the related info right into a DMCA request. You may obtain a pattern DMCA request right here, or search on-line for a lot of different examples.
Throughout the request, I sometimes clarify how they’ll simply establish the content material as mine, equivalent to watermarks, hot-linked photos, or references and hyperlinks to my web site.
Submitting DMCA Takedown Notices to Google
You may have content material faraway from Google through the use of the Report Content on Google service.
I’ve stopped doing this in most eventualities since you solely take away content material that’s on Google. It doesn’t cease the positioning from scraping content material, and regardless of what number of requests you make towards a single web site, Google will proceed to index/rank it.
The right way to Block a Web site from Scraping Content material


In case you have recognized the IP deal with however have had no have a look at the DMCA takedown, you’ll be able to attempt to cease a website from scraping your content material by blocking its IP.
That is one other factor that’s hit and miss. A number of scrapers will use a unique URL than their host to scrape content material and sometimes will use proxies to change the IP. However, many don’t, and this may be efficient.
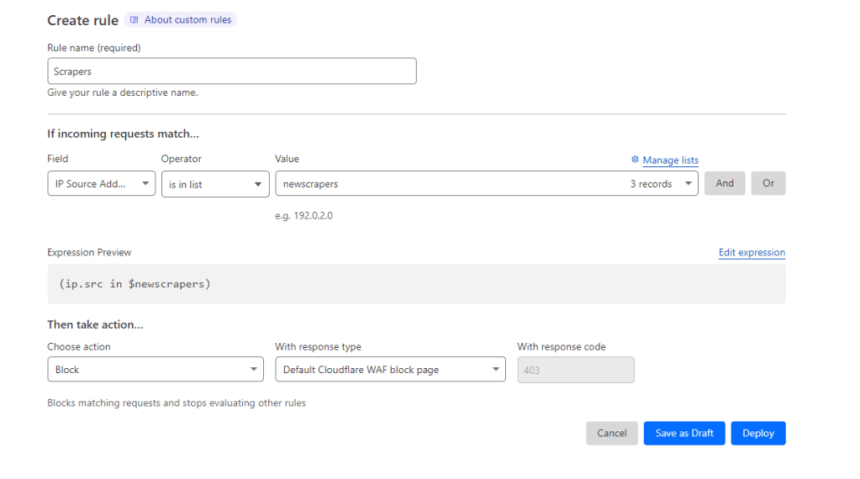
I like to recommend utilizing Cloudflare on your web site and utilizing Cloudflare, you’ll be able to create lists of IP addresses by going to Handle Account > Configurations > Lists.
Then, beneath the area settings, go to Safety > WAF and create a brand new rule.
I set the If incoming requests match the IP supply is in listing then the title of the listing.
Then, I choose Block for the motion and Default Cloudflare WAF block web page.
The right way to Block a Web site from Hotlinking Photos


Cloudflare has a built-in hotlinking prevention instrument, which could be efficient, however I discover it may well generally trigger points with photos displayed on legitimate third-party web sites equivalent to information aggregators like Feedly.
Alternatively, you’ll be able to manually create your individual guidelines by way of the Internet Software Firewall (WAF) once more, or the principles operate.
Blocking picture hotlinking doesn’t make an excessive amount of distinction, but when the scraper is efficiently rating content material, it ought to hopefully wreck the consumer expertise of anybody viewing that content material.
Half 1 of this information could be discovered right here.
Initially revealed on migthygadget.com
I’m James, a UK-based tech fanatic and the artistic thoughts behind Mighty Gadget, which I’ve proudly run since 2007. Captivated with all issues know-how, my experience spans from computer systems and networking, to cell, wearables, and sensible house gadgets.
As a health fanatic who loves working and biking, I even have a eager curiosity in fitness-related know-how, and I take each alternative to cowl this area of interest on my weblog. My various pursuits permit me to carry a singular perspective to tech running a blog, merging way of life, health, and the most recent tech developments.
In my tutorial pursuits, I earned a BSc in Data Techniques Design from UCLAN, earlier than advancing my studying with a Grasp’s Diploma in Computing. This superior research additionally included Cisco CCNA accreditation, additional demonstrating my dedication to understanding and staying forward of the know-how curve.
I’m proud to share that Vuelio has constantly ranked Mighty Gadget as one of many high know-how blogs within the UK. With my dedication to know-how and drive to share my insights, I purpose to proceed offering my readers with partaking and informative content material.







