For those who run a web site that publishes a number of content material, then you’ll virtually definitely expertise different web sites scraping your content material and making an attempt to publish it as their very own.
This will have a damaging affect in your rankings inside Google or different search engines like google. Previously, I’ve had points with a scraper getting their content material listed earlier than mine after which outranking me.
Some scrapers are additionally worse than others. A standard drawback I’ve witnessed is a website will scrape all of your content material after which take away any inner hyperlinks you might have used, generally eradicating all hyperlinks (corresponding to exterior affiliate hyperlinks), and sometimes, they’ll do a poor job of phrase alternative in an try and make it distinctive.
Quite a lot of the time, however not all, they’ll add a supply hyperlink on the backside as if this justifies the scraping as “honest use”.
In all of the instances I’ve skilled when a web site scrapes the content material, they might host the featured picture on their very own web site/CDN however will at all times hotlink another photos inside your content material, which, in principle, will trigger extra knowledge utilization in your server and improve prices or sluggish your server down.
In my case, I’ve had somebody on Fiverr itemizing gigs for automated tech information web sites and promoting them for £60. You’ll be able to most likely guess that they obtain this by means of scraping content material from different web sites, and mine is a kind of.
What affect scraping has on a web site is unknown. In principle, Google needs to be clever sufficient to disregard it as it could inform that the content material is just not distinctive. Many of those websites have 1000’s of pages, but Google solely reveals a number of hundred listed.
Once more, Google ought to ignore them, however these websites will usually create an unpleasant backlink profile, which might doubtlessly have a damaging impact on a web site.
Sadly, many web sites have had a major dip in site visitors and rankings by means of the latest Useful Content material Replace and a number of different Google updates just lately.
It has, subsequently, change into more and more essential to strive and ensure Google sees the unique content material and views the unique website as reliable and authoritative. Having the content material republished on dozens of internet sites is just not going to assist that.
One factor to pay attention to is that it’s best to maybe think about if the time invested in taking down scrapers is price it. Consistently submitting DMCA requests is time-consuming, and in principle, Google needs to be ignoring these websites within the first place.
The way to Establish Web sites Scraping Content material
The primary drawback is figuring out the websites scraping your content material. Within the worst case situations, the web site that’s scraping content material will rank for a similar phrases your content material ranks for, and even worse, outrank you.
Again in 2019, I had a difficulty with Google indexing my website shortly, and the scraper ranked the content material first with me nowhere. Despite the fact that the content material had hyperlinks again to my website and hot-linked photos, Google didn’t determine it as duplicate content material.
Google Search
So, any essential content material you evaluation might be price trying to find easy-to-find phrases. For me, that’s straightforward, I can seek for issues like TP-Hyperlink Tapo P110M Sensible Plug Evaluate.
Ahrefs Webmaster Instruments

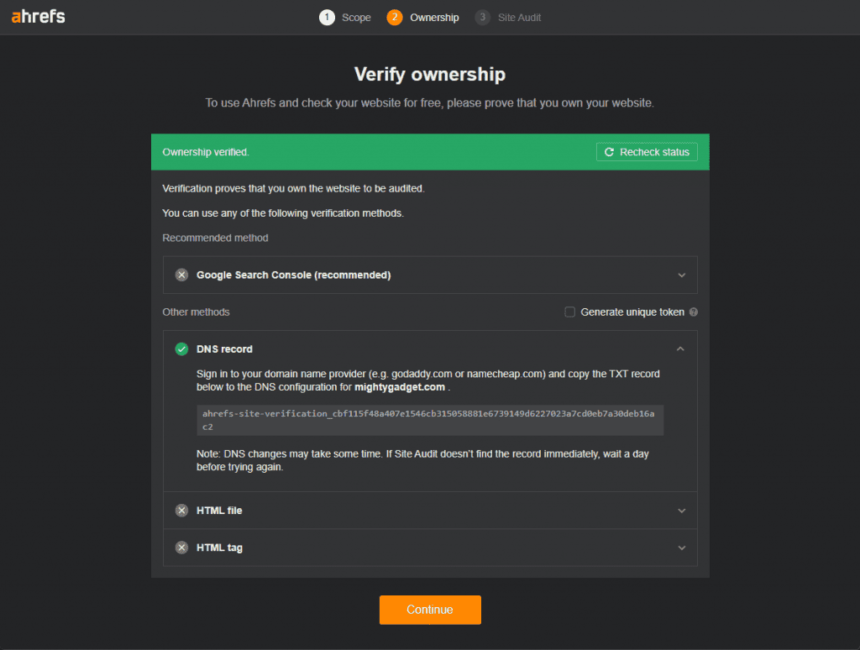
The opposite predominant technique I take advantage of is Ahrefs. It’s a painfully costly service, which is commonly too costly for unbiased bloggers to justify the associated fee. Nevertheless, it’s best to be capable of get primary entry to among the most helpful knowledge freed from cost utilizing the free Ahrefs Webmaster Tools (AWT).
You should affirm possession of the web site by way of Google Search Console or manually by way of a DNS document, HTML file or HTML tag.

After you have entry to Ahrefs, it’s best to be capable of view all of the backlinks your web site has. I’ll usually type the content material by first seeing as you wish to determine individuals actively scraping your content material.
Typically, the backlink might be recognized as a picture; in any other case, you will want to hope they’ve included a hyperlink again to you in some unspecified time in the future within the article.
The way to keep away from hyperlinks being eliminated


Many web sites will take away hyperlinks that return to the host web site, which makes it more durable to determine who the scraper is. The simplest workaround for this, I’ve give you, is to make use of a URL shortener and internally hyperlink to your personal content material by way of the URL shortener. It’s best to then begin seeing hyperlinks from scrapers because the URL shortener 301 redirects again to your web site.
The way to Discover the IP or Host of a Web site Scraping Content material

Figuring out the web site is simply a small step to fixing the issue. Most scrapers both don’t have a working contact type or don’t hassle to answer to take-down requests.
You’ll, subsequently, want to search out the IP deal with and/or internet hosting supplier and submit a DMCA request to them.
Step one I took was to make use of who-hosts-this.com, which is the quickest technique I’ve tried.
If you’re fortunate, you can be supplied with the right host, and you may transfer on to the DMCA course of.
Usually, many web sites registered with Cloudflare and who-hosts-this.com determine Cloudflare because the host.
If this occurs, you will want to make use of the Cloudflare report abuse characteristic. You have to to pick out DMCA, fill out your particulars, and supply examples of the unique work and infringing URL.
They need to shortly reply, offering you with the internet hosting supplier and the contact e-mail for DMCA requests.
An alternate choice I attempted prior to now is to take a look at any pingbacks inside WordPress. I’ve these disabled, so it isn’t a lot use to me anymore.
Different various choices embody:

SecurityTrails: For those who join an account, you’ll be able to see historic DNS information, and this will usually expose what the server and IP have been previous to shifting to Cloudflare
PHP to reveal the scraper IP: This isn’t a perfect choice, however I beforehand had success with utilizing a WordPress plugin corresponding to WPCode to get the consumer IP and output it on the backside of a submit. When a scraper copies the content material, it copies the IP. For Cloudflare, it might usually present the CloudFlare IP, however
The code I used was:
$ip = getenv("HTTP_CLIENT_IP")?:
getenv("HTTP_X_FORWARDED_FOR")?:
getenv("HTTP_X_FORWARDED")?:
getenv("HTTP_FORWARDED_FOR")?:
getenv("HTTP_FORWARDED")?:
getenv("REMOTE_ADDR");Then, you’ll be able to output $ip nonetheless you want. Lately, this hasn’t appeared to work, as I simply get the IP for websites like Yandex.
There’s additionally the mod_cloudflare for Apache, which is the official module that permits you to seize actual IP addresses. The Cloudflare documentation states that is not up to date, however the mod_remoteip works with working programs corresponding to Ubuntu Server 18.04 and Debian 9 Stretch. CloudFlare has a guide on restoring the original visitor IP.
Within the subsequent a part of this information, I’ll cowl submitting DMCA copyright takedown notices to hosts, submitting DMCA requests to good, and the best way to block websites from scaping content material and hotlinking photos.
Initially printed on migthygadget.com
I’m James, a UK-based tech fanatic and the artistic thoughts behind Mighty Gadget, which I’ve proudly run since 2007. Captivated with all issues know-how, my experience spans from computer systems and networking, to cell, wearables, and good house gadgets.
As a health fanatic who loves working and biking, I even have a eager curiosity in fitness-related know-how, and I take each alternative to cowl this area of interest on my weblog. My numerous pursuits permit me to carry a novel perspective to tech running a blog, merging way of life, health, and the most recent tech tendencies.
In my tutorial pursuits, I earned a BSc in Info Techniques Design from UCLAN, earlier than advancing my studying with a Grasp’s Diploma in Computing. This superior examine additionally included Cisco CCNA accreditation, additional demonstrating my dedication to understanding and staying forward of the know-how curve.
I’m proud to share that Vuelio has constantly ranked Mighty Gadget as one of many high know-how blogs within the UK. With my dedication to know-how and drive to share my insights, I goal to proceed offering my readers with participating and informative content material.







